- Voorbereiding
- Hallo wereld
- Extern publiceren
- Persistente volumes
- Geautomatiseerd uitrollen
- Applicatie publiceren
Red Hat OpenShift Container Platform op GCP
Referentie Implementatie: Haven op Red Hat OCP op Google Cloud Platform
Deze referentie implementatie installeert een OpenShift cluster op Google Cloud Platform (GCP). Het resulterende cluster wordt door uzelf beheerd.
Voorwaarden
Zorg dat er een project is aangemaakt binnen GCP, waar een quotum is gedefinieerd dat
voldoende ruimte heeft voor een installatie van OCP met OCS. Het gaat hierbij om de
quota voor Compute Engine API / Persistent Disk SSD (GB) en Compute Engine API
/ CPUs.
Het minimum voor Persistent Disk is 1280GB (dit is inclusief storage voor de OCS nodes). Voor CPUs is het minimum 72, uitgaande van de standaard instance groottes. De standaard instance grootte voor workers en masters is n1-standard-4. Voor OCS nodes is de standaard instance grootte n1-standard-16.
Binnen het project in GCP moeten een service account worden aangemaakt, moeten er verschillende permissies aan de account worden toegekend, en moeten er APIs beschikbaar gemaakt worden.
De precieze omschrijving van wat er aan voorwaarden is voor we met de daadwerkelijke installatie kunnen beginnen, staat in de OpenShift documentatie^1.
Basis installatie
Deze basis installatie gaat uit van OpenShift 4.7 op GCP met OpenShift Container Storage 4.7.0 en is geschreven in mei 2021. Bij gebruik lang na deze tijd kunnen screenshots en versienummers afwijken. De volledige documentatie voor het installeren van een OpenShift cluster op GCP staat op de OpenShift documentatie website^2.
Stap 1: Download de OpenShift installer vanaf
cloud.redhat.com
en pak het bestand uit naar de lokale schijf. Download ook de OpenShift command-line
tools van die pagina: hierin zit het oc commando dat we later zullen gebruiken.
Stap 2a: Om een cluster met de standaard instellingen aan te maken, voer het volgende commando uit. Het installatiebestand vraagt om een service account key bestand in JSON formaat. Het proces om zo'n service account key bestand aan te maken staat omschreven in de documentatie van GCP^3.
./openshift-install create clusterStap 2b: Om een cluster aan te maken met aangepaste instellingen, voer het volgende
commando uit. Ook hier vraagt het installatie bestand om de informatie uit stap 2. Dit
commando genereert een install-config.yaml bestand, dat bijvoorbeeld aangepast kan
worden om bijvoorbeeld workers uit te rollen met een grotere maat, of een groter aantal.
./openshift-install create install-configNa de aanpassing van het install-config.yaml bestand, voert u het installatie
bestand nogmaals uit (er vanuit gaande dat install-config.yaml in dezelfde directory
staat als de installer):
./openshift-install create cluster --dir=.Onafhankelijk van of u stap 4a of 4b gevolgd hebt, duurt de installatie circa 45 minuten. Daarna hebt u een werkend OpenShift cluster, dat al voor het grootste deel voldoet aan Haven.
Volledige Haven compliancy
Om volledig compliant te zijn, heeft het OpenShift cluster nog twee aanpassingen nodig: er moet een log aggregator worden geïnstalleerd, en er moet RWX storage beschikbaar worden gemaakt.
RWX Storage
Om RWX storage te kunnen aanbieden op GCP, maken we gebruik van OpenShift Data Foundations (vroeger "OpenShift Container Storage"). Dit zorgt voor optimale performance en optimaal gemak bij het aanbieden van block, file en object storage.
Om een klein OCS cluster te maken, hebben we drie nodes op GCP nodig die we kunnen voorzien van de juiste software. Deze nodes draaien binnen het OpenShift cluster, en worden aangemaakt en gemanaged als MachineSets. Dit betekent dat OpenShift de life cycle van de nodes en de daarop draaiende software kan beheren.
Hier staat een voorbeeld template voor een machineset.
Uitgebreide informatie over het aanmaken van een machineset staat in de OpenShift documentatie.
De voorbeeld machineset gebruikt europe-west4 (Eemshaven) en rolt in europe-west4a, europe-west4b en europe-west4c een machine uit, drie in totaal. De template dient te worden aangepast als er in een andere region wordt uitgerold. Ook moet er in dit template een CLUSTERID en een PROJECTID worden ingevuld. Deze informatie kan uit een bestaande machineset in het cluster worden gehaald.
Na het aanpassen van het machineset.yaml bestand, passen we het als volgt toe:
oc create -f machineset.yamlNadat de drie machinesets zijn aangemaakt, en er drie machines zijn aangemaakt,
installeren we de storage operator. Hiervoor gaan we naar de OperatorHub in de OpenShift
GUI, en zoeken we op openshift container storage:
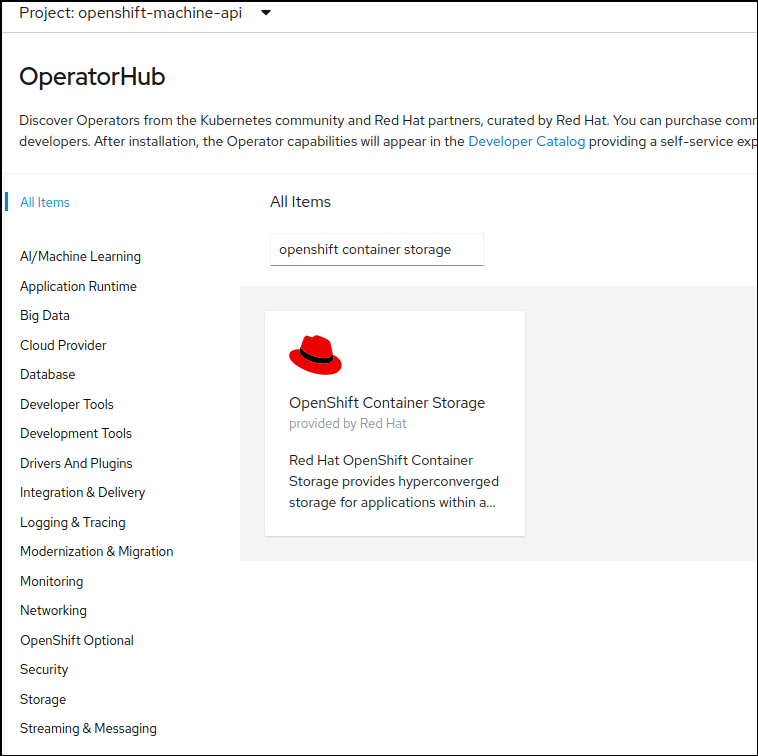
Klik op de operator, en vervolgens op Install:
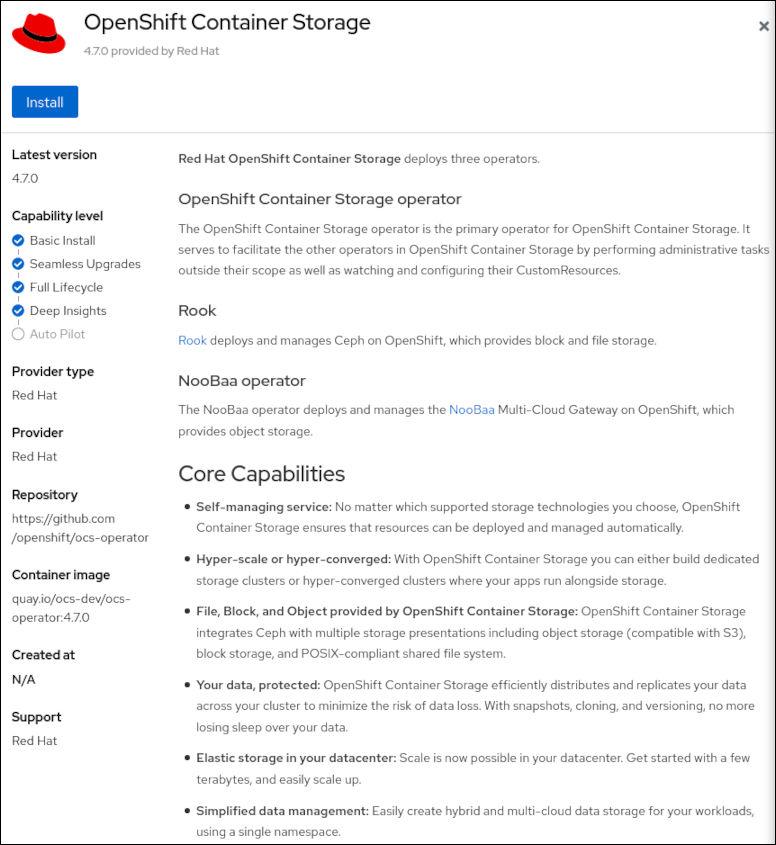
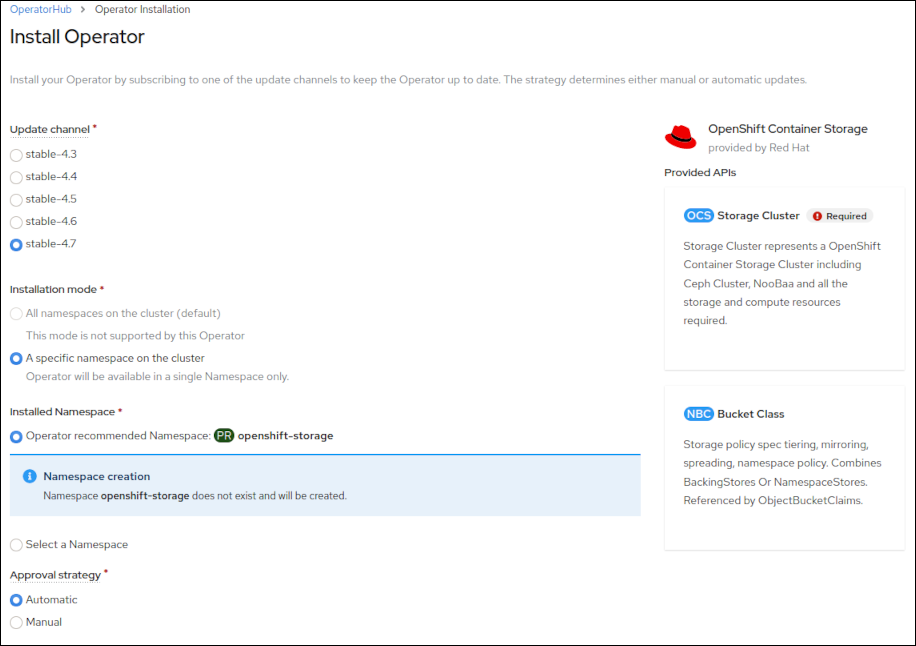
Zorg dat de parameters staan zoals op het screenshot hieronder, en klik nogmaal op Install. Dit
installeert de storage operator.
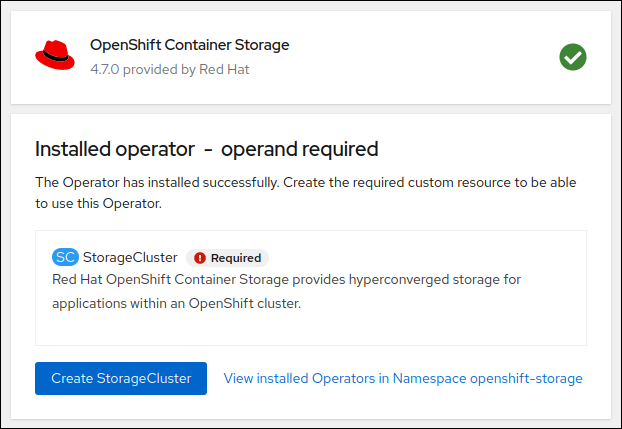
Na het installeren van de storage operator, hoeven we alleen nog het daadwerkelijke
storage cluster aan te maken. Klik in onderstaand scherm op View operator en
vervolgens op Create instance op het kaartje waarop OCS Storage Cluster staat:
Voor ons "aan de slag" vullen we op de volgende pagina in dat we gp2 onderliggende storage willen gebruiken, en geven een capaciteit aan. De operator zorgt zelf voor het aanmaken van de onderliggende storage.
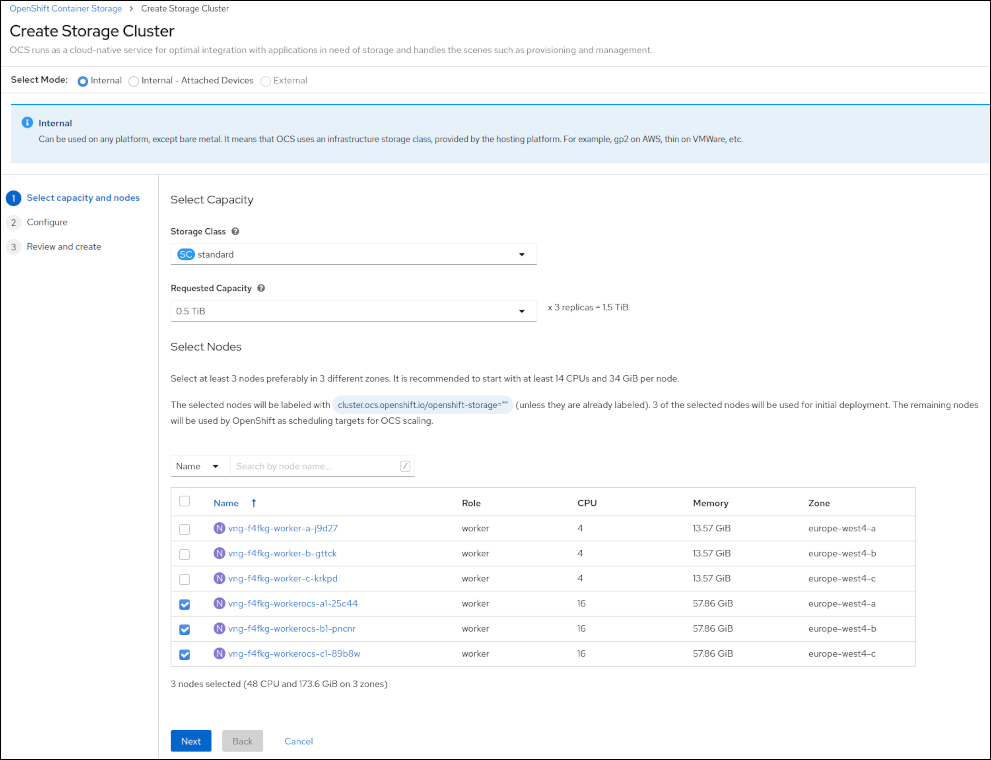
Tot slot vinken we de drie nodes aan die we aangemaakt hebben met de machineset
hierboven. De verdere installatie loopt vanaf hier automatisch. Na de installatie zijn
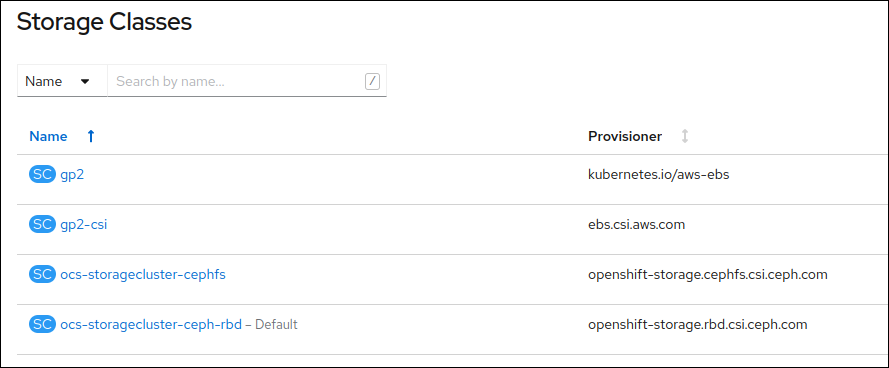
nieuwe storage classes beschikbaar vanuit OpenShift Container Storage:
ocs-storagecluster-cephfs, een file system based oplossing, met RWX mogelijkheden, en
ocs-storagecluster-ceph-rbd, een block storage oplossing met high availability en
replicatie.
Als laatste stap configureren we ocs-storagecluster-ceph-rbd als standaard storage:
oc patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
oc patch storageclass ocs-storagecluster-ceph-rbd -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
De volledige documentatie van OpenShift Data Foundations is hier te vinden.
Log aggregator
Red Hat OpenShift wordt geleverd met geïntegreerde logging stack, maar die wordt niet automatisch geïnstalleerd om gebruikers de mogelijkheid te geven met een andere logging stack te werken.
In deze referentie implementatie installeren we de standaard logging stack achteraf, om compliancy met Haven te bereiken.
Om de logging stack te installeren, volgen we de handleiding.
Hierin lezen we dat we eerst de ElasticSearch operator op het cluster moeten installeren, en vervolgens de cluster-logging operator.
Vervolgens creëren we een instance ClusterLogging. De verdere installatie van Fluentd, ElasticSearch en het Kibana dashboard gaat vanzelf. Na deze installatie is er een log aggregator beschikbaar, compleet met zoekmachine en dashboard.
Onderhoud
OpenShift is gebaseerd op zogenaamde operators[^4]. Heel kort gezegd zijn operators stukjes software die in staat zijn om een ander stuk software te beheren. Door gebruik van operators is OpenShift in staat om een groot deel van zijn eigen onderhoud te doen.
Als er een update voor een OpenShift cluster beschikbaar is, is dat zichtbaar in de OpenShift console. Updates kunnen op een geschikt moment door een druk op de knop worden geinstalleerd. Als een OpenShift update wordt geinstalleerd, worden ook de onderliggende VMs automatisch geupdatet.
Bovenstaande geldt zowel voor updates tussen minor releases (bijvoorbeeld van 4.6.23 naar 4.6.24) als voor updates tussen major releases (bijvoorbeeld van 4.6.24 naar 4.7.1).
Bij het installeren van additionele operators (zie hieronder) kan worden aangegeven of de operators zichzelf automatisch mogen updaten, of dat updates handmatig geinitieerd moeten worden. De keuze voor automatische of handmatige updates hangt af van verschillende keuzes die buiten de scope van dit document vallen.
Vervolgstappen
Operators
Ook software die op OpenShift draait, wordt vaak beheerd door een operator. Vanuit de ingebouwde OperatorHub kan additionele software worden geinstalleerd, zoals bijvoorbeeld een Kafka cluster of serverless functionaliteit. Ook veel software van derden wordt via de ingebouwde OperatorHub op OpenShift aangeboden, zoals geclusterde PostgreSQL databases, API gateways, en monitoring software.
Ga voor de OperatorHub in het menu aan de linkerzijde naar Operators -> OperatorHub.
Verder lezen
[^4]: Zie ook: https://www.redhat.com/en/topics/containers/what-is-a-kubernetes-operator
Aan de slag met Haven?
In onze technische documentatie wordt de standaard toegelicht en beschreven hoe u Haven kunt installeren op uw huidige IT infrastructuur. Bovendien hebben we een handreiking programma van eisen beschikbaar gesteld om het inkopen van Haven te vereenvoudigen. Of neem contact met ons op, we helpen u graag op weg!